Kubeflow Challenge
About the challenge
For the DigitalOcean Kubernetes Challenge, I chose to explore Kubeflow as MLOps / how to manage models at scale in production is a area I’m begining to explore professionally.
For this challenge, my goal was to deploy & run a model with Kubeflow running in DigitalOcean, along the way gaining a better understanding of how Kubeflow solves problems in the ML lifecycle.
Resources
Putting the resources I used up front in case it’s useful to others who want to explore Kubeflow.
Github Repo for this article: nathanamorin/ml-platform-challenge
Deploying
Deploying Kubernetes on DigitalOcean
Coming from managing Kubernetes on AWS, deploying a cluster on DigitalOcean was very simple. For this exploration, I used the console the create the cluster with 3 basic nodes (2 vCPU 4 GB RAM) & later scaled this to 5 nodes. I also used the 1-Click app feature to deploy a Nginx load balencer which auto deployed a DigitalOcean LB. This process was very clean, taking the complexity out of deploying a basic Kubernetes cluster.
Deploying Kubeflow
TLDR: run make kubeflow_base (run multiple times until all objects are successfully applied), make kubeflow_ingress, modifying deploy/ingress.yaml with your hostname, and make auth (follow prompts to create password for default user) in the article repo.
To deploy Kubeflow, I first copied the Kubeflow Manifests repo to vendored/kubeflow in the article repo & followed the instructions in the repo for building the kustomize templates.
However, I ran into issues deploying the full kustomize template with kubectl apply. Part of the way through, kubectl apply would be unable to send requests to the Kubernetes API server (I assume this is some form of token / timeout issue). To resolve this, I split the single kustomize built template into separate files for each object & use kubectl apply to deploy these individually (see deploy/kubeflow). These can be applied with make kubeflow_base. There are dependency issues between the objects in these, so must repeat this command until all the objects are successfully deployed.
In my experimentation later running pipelines in Kubeflow, I also found I needed to modify the default template to use emissary rather than docker as the pipeline container runtime executor (ref).
After the base kubeflow deploy is installed, you can modify deploy/ingress.yaml to include your own hostname (setting the DNS record to point to the DigitalOcean LB) & then run make kubeflow_ingress. Finally, make sure to run make auth to change the default user password. Once this is done, the kubeflow dashboard will be available at the hostname specified.
Running a model on Kubeflow
Kubeflow provides a Jupyter notebook environment for data exploration.

To test this, I created a example Jupyter notebook with the default environment (it allows specifying custom docker images for non standard environments)
To test & explore how Kubeflow operates, I ran a few of the example pipelines provided. In particular, I thought the XGBoost pipeline was an interesting end to end example.
Kubeflow has the concept of an Experiment which is a pipeline instantiated with a set of prameters. An Experiment is then associated with one or more Runs, as can be seen in the below screenshots.
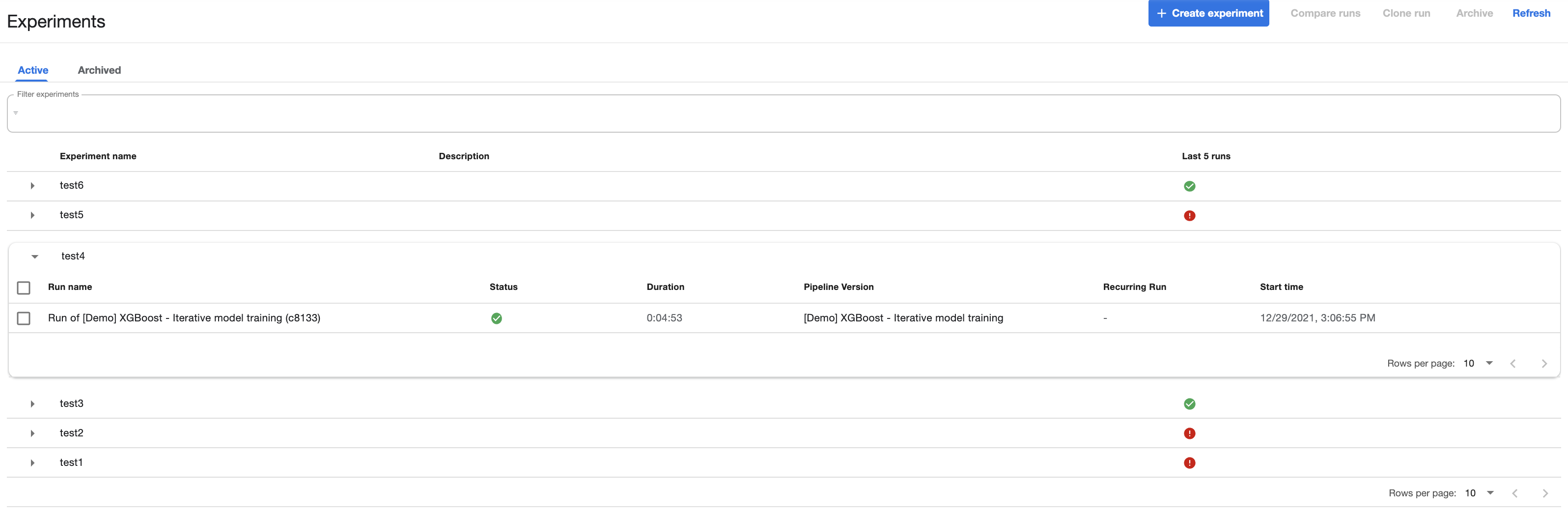
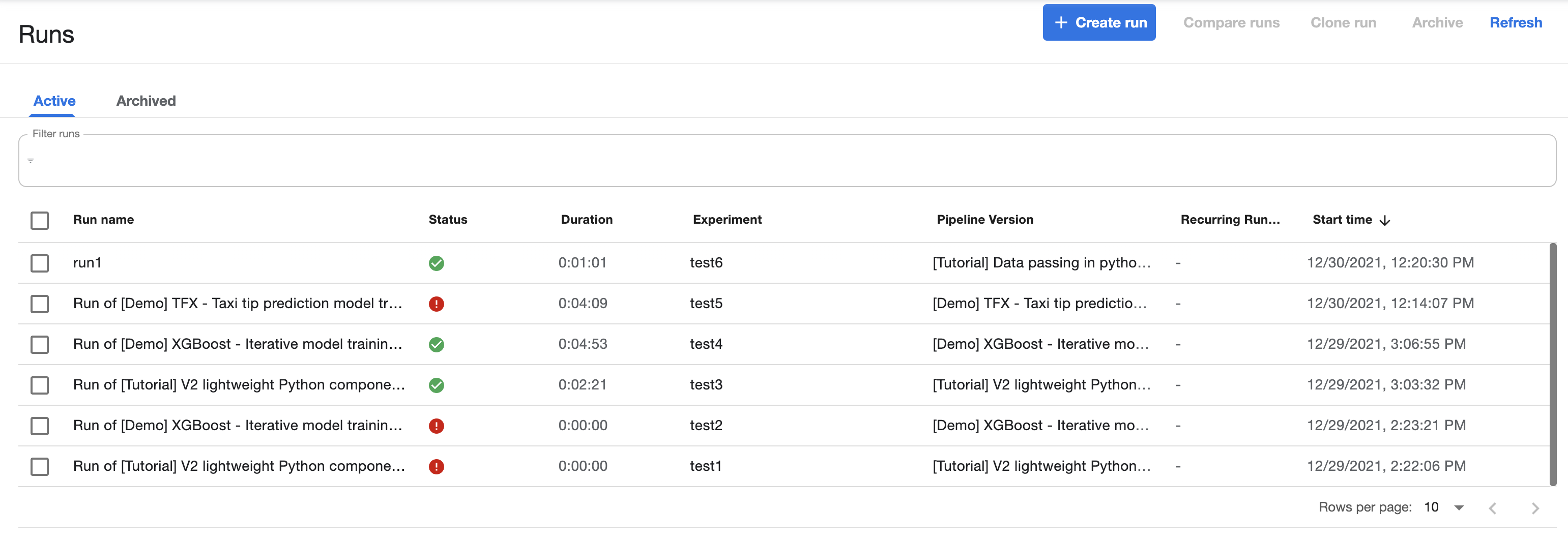
When a Run is executed, pods are created in Kubernetes to run the associated steps. For the first few runs, it was useful to view the pods / any associated errors directly in the kubectl as not all these messages are forwarded well into the Kubeflow UI.
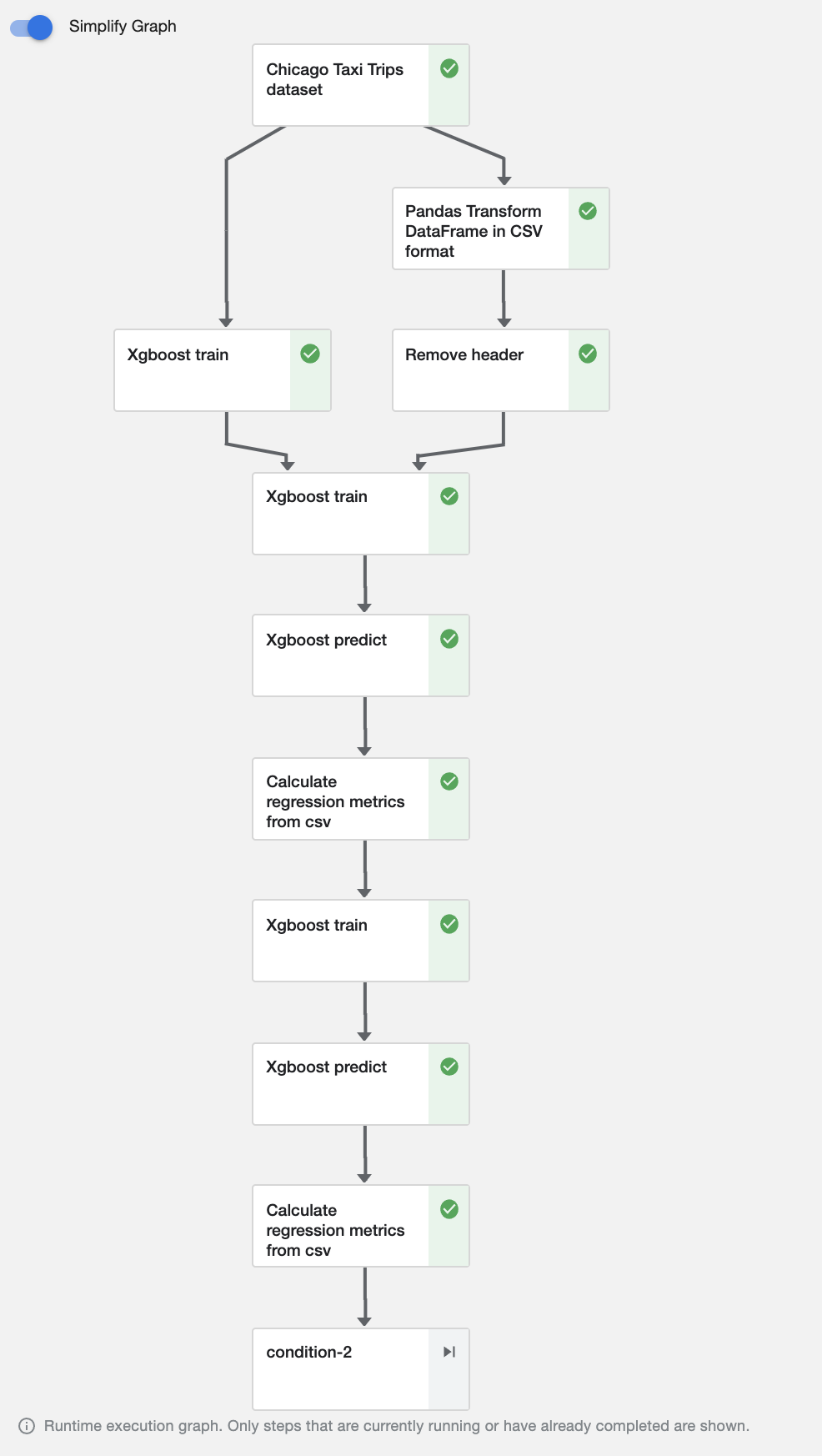
As a job is running, Kubeflow allows viewing the graph of associated dependencies between the steps.
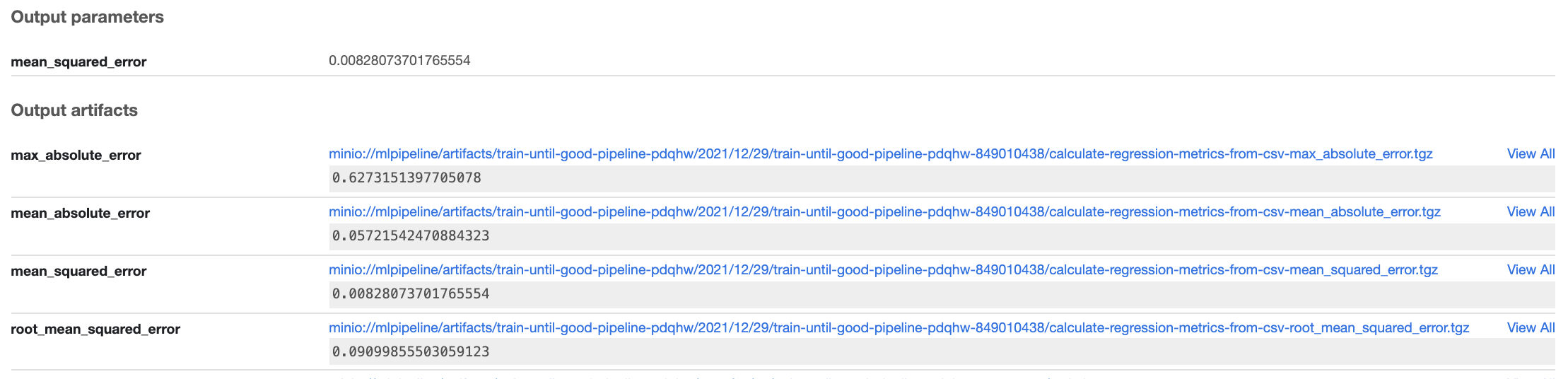
Once a steps is complete, you can any output parameters.
Final Thoughts
Although there are some hurtles to getting started with Kubeflow, overall the setup / day one usage is fairly straightforward.
One thing I particularly liked was how pipelines can be configured with the kfp python library & compiled into yaml workflow definitions that can be executed in Kubeflow / Kubernetes. This makes configuring these pipelines much simpler for data scientists & also presents the oportunity to use a CI process for building / deploying these workflows into a production cluster.